One Last Time with Team Interceptions, Part 4

So, the
question came up- why not generic team charts, like/ similar to batting cards?
Let’s look
first at the problem batting cards were trying to solve. Take a Sixties baseball team and the pitchers
(in sum) will bat about as much as 2/3rds of a regular, and mostly not very
well. But you get exceptions. When you try to cut a team’s total pitcher
batting into the individuals you eventually get a handful of relief pitchers who
banged a triple in five at bats, or a homer in ten at bats, and unless you were
Earl Wilson in 1968 a personal card reflecting this this is somewhat
unrealistic.
Most
pitchers stink when batting so (other than personal cards) there are two ways to
solve this – you can aggregate the whole team (a method I use in Statis-Pro
Baseball, which is going to have the effect of grouping a pitcher with no power
like Mickey Lolich in with Earl Wilson) BUT it is just easier to manage and
works for probably 25 out of 28 teams. Or you can group the pitchers by type. This is what Strat-O-Matic did, first with
four pitcher’s batter’s cards, and then with eight during the baseball card game’s
Golden Age.
They chose
five cards for pitcher with no power, and three for pitchers with power:
IF
NO HR'S OR AB/HR>=68
Bavg
Card
.000
- .134 1
.135
- .179 2
.180
- .224 3
.225
- .269 4
.270
+ 5
IF
AB/HR < 68
Bavg
Card
.000
- .199 6
.200
- .249 7
.250
+ 8
One look and you can see the first
five cards are probably reasonably spaced; this is probably not a bad way to
model pitchers with no power. No, it won’t accommodate pitchers with a lot of
walks or extra base hits past a certain point but those are rare anyway. It is the last three cards that bother me,
that range for Card 6 is from truly lousy pitcher’s hitters who catch hold of
one (here’s looking at you, Bartolo Colon) to pretty good hitters who might have
reasonable power, like Dave McNally or 1972 Bob Gibson. That range is too broad for Card 6. Now- does it matter?
Well SOM baseball fan Flying Pickle
actually put all pitcher’s batting cards in a spreadsheet about fifteen years
ago, and here were the results:
Figure 1: Pitchers Batting Cards,
1901-2008

There aren’t that many Card 6 guys anyway, and what would they get? For a number one starter maybe 40-50 AB? Cards 6-8 are less than seven percent of all pitchers who bat. The question of whether there ought to be ten or twelve pitcher’s batting cards (more than eight) is mooted by the fact these players are peripheral to their team’s overall offensive experience. Most players will want the simpler answer or the most complex, i.e. individual cards.
And that brings us to Team
Interception Returns. I’m pleased that I
finally got the last two teams from 1980 to finish my Wideboys collection; this
final event was over a year in the making. I might be poorer, but I sure have a smile on
my face, because I’ve been horsing around now for a day or two with this season’s
cards in my off time. One might say I
have 1980 on my mind. Two of my favorite teams are 1980 LA and 1980 Dallas, the
Wild Card runts of the 1980 NFC despite good records. 1980 LA is an offense first team with one of
the team’s weaker run defenses of the last decade, they finished with a pretty
good turnover plus minus but with terrible kicking. They still got 405 points even with Haden in
for fifty attempts, more than ten percent.
The Cowboys led the 1980 NFL in scoring in spite of having the ninth
best offense in yards. Dallas had Tony Dorsett push for 11 TDs and 1185 yards
on the ground while five other runners chipped in 991 yards and another ten
TDs. Dallas scored like this year’s Detroit Lions, but in one less game, and
the Rams were not far behind, even though neither team made a lot of kicks.
What was setting them up?
Aha!
The 1980 Season’s interception returns helped to define the 1980 season!
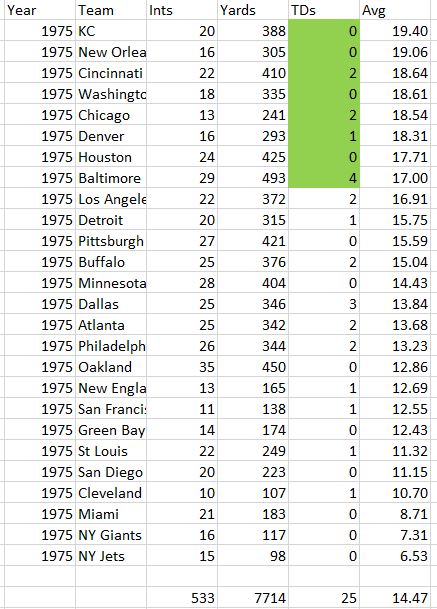
Figure 2: A sampling of team
interception returns by team from the 1980 season:

The World Champions and two of the ten
playoff teams are in the top yardage tier, teams that averaged more than thirty
yards of interception returns a game.
The next tier is limited more by opportunities, as Denver would have led
the league in yardage had they matched the Oakland interception total. Still, we see another three playoff teams
there, and only one team, Philadelphia in the bottom tier. This is not uncommon. LA and Dallas might have been 10-6 type teams
had their returns not elevated them to 11-4 (with Ferragamo) for LA and 12-4
for Dallas. Their team returns were not peripheral to their success, they
were the key to it. Another way to look at it is Atlanta, also 12-4, was
plus sixteen in turnovers and had great special teams, a plus kicker in Mazzetti,
a good punter in James, good coverages, and a top three punt return unit. All that offset an iffy pass defense. Why
shouldn’t Dallas and LA get the same boost from their secondaries?
One last point I’ll make is the seasonal record even at first blush for each team holds a lot of information. Let’s look at 1980 Dallas- the first rung of data that you see in PFR:
Figure 3: 1980 Dallas Return Results First Pass from
PFR: (Click to make bigger)

So, we have the longests. And if a guy has two returns with a longest
of 2 yds that means the other return is a zero.
If a guy has 3 returns for 56 yards with a longest of 56 yards the other
2 are zeros. Just at first glance you
have half of the returns and you can guess they might be “chunky”.
Looking up the weekly records by
player for Thurman, Waters, Breunig, and Wilson finishes the record. Thurman’s best day saw him get two for 42
yards with a longest of 35. That means
the other is seven yards. Here’s how it
fills out:
Figure 4: 1980 Dallas Final Record

Figure 5: 1980 Dallas Returns

I could see maybe adding in that 56
yarder in the twelve spot and cutting the +12 yard result in the seven spot to +9
but that increases the fractional TD pct by a few points, so I didn’t do that. You can see the chunky nature of the team’s
returns in the nine 30 (or so) yard chances they have out of 36. In the
final analysis once you get this close it’s not going to matter, Mike might do
better with his reckoning, but it’s a pretty good chart. Taking into account
returns “not returned using the rule for that” for 0 yards this chart is manifestly
better at describing 1980 Dallas than the stock chart.
We’ll put one last chart up there,
1980 Seattle:
Figure 6: 1980 Seattle Seahawks Team Card (23/95
yards, 0 TDs, 4.1 yds per return)

I’ll let gamers be the judge as to
whether or not a generic chart is a better fit for this team’s efforts. In my opinion, though, team interceptions are
more like running cards then baseball’s pitcher batting cards, where there can
be many ways to get to the final rushing stats line. If there weren’t we could
just use the extra runners from the set of extra player cards and change a few
results to make a season. And, of course, we don’t do that. We can do better than that.
Fred Bobberts
Initial Date of Publication: 2/10/2024